NeRF図だくさん解説:ニューラルネットで自由視点画像を生成しよう
73.4K Views
August 25, 23
スライド概要
ニューラルネットを用いて、視点の異なる複数の写真だけから自由視点画像を生成する手法、NeRFの元論文を解説してみました。
カメラ視点を与えたら、画像の生成まで行ってくれるニューラルネットだと思われていますが、実はちょっと違います。
そのよくできた構造と、ニューラルネットというものが持つ可能性など、元論文で語られていた数々の魅力を図だくさんに解説してみました。
機械学習の基礎的な知識がない方でも理解しやすいように、なるべく直感的な説明を心がけてみました。
よかったら覗いていってください
ニューラルネットをGPU向けに最適化するお仕事をしています
関連スライド





各ページのテキスト
NeRF: Representing Scenes as Neural Radience Fields for View Synthesis 図だくさん解説 1
⾃⼰紹介 ROCMan • 来年春から新卒GPUエンジニアの修士2年生 • 深層学習とGPUプログラミングがちょっとわかる • たまに深層学習系の論文読んでスライドにまとめてます twitter垢: https://twitter.com/ROCmannn 2
NeRF: Neural Radience Field 下の図をよく見る 🤔 色んな角度から写真撮って学習させたら、 任意視点からの画像を作れるニューラルネット? Ø ビミョーに間違い。詳しく見ていきましょう 3
⽬次 • NeRFが生まれたモチベーション • Radience Field を用いたレンダリング • NeRFとは • 精度向上の工夫 • positional encoding • 階層型volume sampling 4
実世界の物体をデータ化して眺めたい 実世界の物体をデータ化して、“好きな角度から” 眺めたい場面は多い • VR, AR, etc. アルバム 🤔 色んな角度から写真撮って参照すれば? Ø 撮ってない角度や視点からの見え方は分からない… (光の反射具合etc.) 一部の角度や視点から撮った写真だけから、 未知の角度、視点の画像を予測したい! 視点+角度 Oracle 多分こんなんやで 5
ニューラルネット使おうぜ NNは万能関数近似器! 視点と角度から写真を返すNN作れるはず! 視点+角度 Oracle Ø理屈の上ではそうなんだけど… 複雑過ぎる関数は、NNでは学習が困難 お前Oracle全部やれ Øちょっとだけ人間が手助けしてあげよう えぇ… 6
NeRFを⽤いたレンダリングの概略図 NNを使うのは ここだけ! (𝑐! , 𝜎! ) (𝑥! , 𝑦! , 𝑧! , 𝜃! , 𝜙! ) 点の色 & 不透明度 点の座標 & カメラの方角 カメラ視線上の点をsampling 𝜎 $ " 𝑇! 1 − exp −𝜎! 𝛿! 𝑐! !"# 𝑖 𝜎 各点の色と不透明度 を計算 視線1本ごとに 各点の色と不透明度 を集計 𝑖 いい感じに足し合わせて スクリーンの1pixelを計算 1stepずつ見ていこう 7
① カメラからrayを発射 1. カメラの視点と、スクリーンの位置を決定 2. カメラからスクリーンの各pixelへrayを発射 3. ray上の点を細かくsampling 4. それらの点の座標(𝑥, 𝑦, 𝑧)と、そこから カメラを見た時の立体角(𝜃, 𝜙)を計算しておく (𝑥' , 𝑦' , 𝑧' , 𝜃' , 𝜙' ) 8
② NNに⾊と不透明度を聞く ray上の各点 𝑥, 𝑦, 𝑧 (にある粒子) の • (𝜃, 𝜙)方向に発している色 :𝑐 • 不透明度 :𝜎 ☜あとで重要! をNNに聞いていく ✏ NNは、空間上の全ての点が、 𝑥' , 𝑦' , 𝑧' “どの方向に、どんな色を発しているか”(輝度場) (𝜃' , 𝜙' ) を知っているOracle (𝑐' , 𝜎' ) Ø この輝度場(Radience Field)をNeural Netで表してるから、 Neural Radience Field (NeRF) Ø NNの構造&学習法は後ほど詳しく 9
③ 各点の⾊を積み重ねる (volume rendering) 1. 前ページでray上の各点の色とσをGET 2. 下式で, rayとscreenの交点のRGBを計算 点 i から放たれた光のうち、 散乱されずにカメラまで届く割合(的な) 点 i が放つ光の強度 点 i のRGB 𝛿: 隣接点の距離 カメラから点 i まで にある全点の不透明度σの合計 ごちゃってるから一個ずつみていこう 10
③ 各点の⾊を積み重ねる (volume rendering) '.+ ∑ 𝐶 𝑟 = ∑, 𝑇 1 − exp −𝜎 𝛿 𝑐 , 𝑤ℎ𝑒𝑟𝑒 𝑇 = exp(− ' ' ' ' '*+ ' -*+ 𝜎- 𝛿- ) 点 i のRGB 11
③ 各点の⾊を積み重ねる (volume rendering) '.+ ∑ 𝐶 𝑟 = ∑, 𝑇 1 − exp −𝜎 𝛿 𝑐 , 𝑤ℎ𝑒𝑟𝑒 𝑇 = exp(− ' ' ' ' '*+ ' -*+ 𝜎- 𝛿- ) 点 i のRGB 𝛿: 隣接点の距離 • 1 − exp −𝜎' 𝛿' 𝜎 のお気持ち Ø 点 i が放つ光の強度 Ø ざっくり𝜎! (不透明度)と意味は同じだと考えて良い(右図) cf.) 不透明度が高い点ほど見えやすい(何らかの物体がある) (expが式に含まれる背景:直進光は、進む距離に対して指数関数的に減衰) • 1 − exp −𝜎' 𝛿' 𝑐' のお気持ち 𝛿! 𝑖 大体同じグラフ 1 − exp(−𝜎! 𝛿! ) Ø 点 i がカメラに向けて放つ光(光の強さ込み) (不透明度が高い点ほど、より多くの光を反射) 𝑖 12
③ 各点の⾊を積み重ねる (volume rendering) '.+ ∑ 𝐶 𝑟 = ∑, 𝑇 1 − exp −𝜎 𝛿 𝑐 , 𝑤ℎ𝑒𝑟𝑒 𝑇 = exp(− ' ' ' ' '*+ ' -*+ 𝜎- 𝛿- ) 点 i がカメラに向けて放つ光 𝜎 • 𝑇' のお気持ち Ø 点 i が放つ光のうち、他の点に遮られずカメラまで到達する割合 𝑖 !&# 累積和 & -1倍 − " 𝜎% 𝛿% • 𝑇' 1 − exp −𝜎' 𝛿' 𝑐' のお気持ち %"# Ø 点 i から放たれ、他の点に遮られずにカメラまで到達する光 Øこれをray上の全点 i について足して、 やっとスクリーンの1pixelをGET 𝑖 $%# exp(− & 𝜎! 𝛿! ) !"# 𝑖 13
NNの中⾝ 14
NNはあくまで全体の⼀部 NNを使うのは ここだけ! (𝑥! , 𝑦! , 𝑧! , 𝜃! , 𝜙! ) カメラ視線上の点をsampling 点の座標 & カメラの方角 (𝑐! , 𝜎! ) 点の色 & 不透明度 … 結局、NNの担当は、ある点の座標(𝑥, 𝑦, 𝑧)と向き(𝜃, 𝜙)から以下を吐くだけ • 不透明度 :σ • (𝜃, 𝜙)方向に発している色 :𝑐 15
NNの内部構造 • 重要なパーツは主に2つ • 全結合層 • Positional Encoding 𝜎 ReLU Positional Encoding (𝑥, 𝑦, 𝑧) 〜 d=1 中 間 値 中 間 値 全結合 + ReLU + Concat 中 間 値 全結合 + ReLU x5 d=60 に変換 d=257 d=316 Positional Encoding 極座標を (𝜃, 𝜙) + 中 間 値 全結合 + ReLU 全結合 + sigmoid C x3 d=256 3次元座標 全結合 中 間 値 Concat (𝑑4 , 𝑑5 , 𝑑6 ) 〜 中 間 値 d=20 d=276 d: 次元数 16
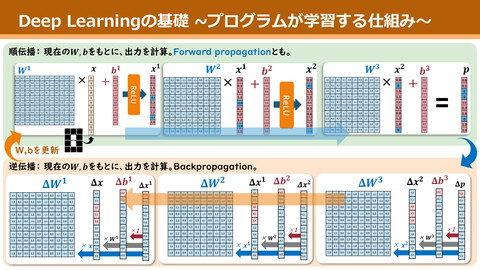
全結合層 𝑦 = 𝐴𝑐𝑡𝑖𝑣𝑎𝑡𝑒(𝑥𝑊 + 𝑏) ざっくり言うと • ベクトル世界での掛け算と足し算 活性化関数 ReLU 適切な活性化関数を挟み、より複雑な関数を作る 𝑥 * 𝑏 𝑊 𝑦 Sigmoid 非線形性を生み、 表現力が向上 17
Positional Encoding 3次元座標を三角関数の周波数の世界に埋め込む 𝑥, 𝑦, 𝑧 → (𝜸 𝑥 , 𝜸 𝑦 , 𝜸 𝑧 ) 例)L=3とすると 𝑥 = 0.5は、以下のようなベクトルに変換 𝜋 𝜋 𝛾 𝑥 = (sin , cos , sin 𝜋 , cos 𝜋 , sin 2𝜋 , cos 2𝜋 ) 2 2 = (1, 0, 0, −1, 0, 1) 🤔 何故こんなことを?情報量は結局同じでは? 18
論⽂⽈く、NNが画像の⾼周波成分を検出しやすい • 画像中の細かいエッジ部分 Ø 画像をフーリエ変換した際の高周波成分にあたる 低周波 高周波 生の座標だと、NNは低周波成分だけ学習しがちらしい Ø positional encodingすると、NNが高周波成分を捉えやすくなる 🤔 説明は簡易的であまりピンとこない 個人的な解釈を2つご紹介 19
個⼈的な解釈① 微弱な座標の変化が際⽴つ 例)L=3の時に、𝑥 = 0.5から0.6に変化した時の違いを見てみる 𝛾 0.5 = (sin 𝛾 0.6 = (sin ⇔ 7 8 97 : , cos , cos 7 , sin 𝜋 , cos 𝜋 , sin 8 97 ;7 ;7 , sin , cos : : : 2𝜋 , cos 2𝜋 ) , sin +87 : , cos +87 : ) 𝛾 0.5 = ( 1, 0, 0, −1, 0, 1) 𝛾 0.6 = 0.95, −0.3, −0.59, −0.81, 0.95, 0.3 あまり値が 変化しない 低周波 やや値が 変化 大きく 値が変化 高周波 • わずかな座標の違いで粒子の質が激変するエッジ部分 Ø 高周波成分に注目すれば良い • 長い座標区間にまたがって同じような粒子が並ぶ部分 Ø 低周波成分に注目すれば良い 20
個⼈的な解釈② 周期的に並ぶパターンを捉えやすい 特定の周期で似たパターンが並ぶものは多い ØP.E.により、この周期をNeRFが捉えやすくなる 例)右下図の赤3点を見る • (𝑥, 𝑦)座標系 𝑦 • (−0.5, 0.5), (0, 0.25), (0.5, 0) バラバラな 点なのね • P.E.(𝐿 = 3)後の座標 • −1, 0, 0, −1, 0, 1 , • 0, 1, 0, 1, 0, 1 , • 1, 0, 0, −1, 0, 1 , 1, 0, 0, −1, 0, 1 " " , # # , 1, 0, 0, −1 0, 1, 0, 1, 0, 1 𝑥 𝑂 一応、位置的な 関連があるのね Ø 周期に対応する値が揃い、NeRFが法則性を発見しやすくなる 21
NeRFの学習⽅法 22
NeRFは微分可能な処理しかやっていない NN部含め、実は全ての工程が微分可能(になるよう設計されている!) Ø 誤差逆伝播法が使える Ø NN部の勾配が求められる! 微分可能! (𝑐$ , 𝜎$ ) (𝑥$ , 𝑦$ , 𝑧$ , 𝜃$ , 𝜙$ ) 点の色 & 不透明度 点の座標 & カメラの方角 カメラ視線上の点をsampling 微分可能! 𝜎 & & 𝑇$ 1 − exp −𝜎$ 𝛿$ 𝑐$ $"# 𝑖 𝜎 𝑖 各点の色と不透明度 を計算 視線1本ごとに 各点の色と不透明度 を集計 いい感じに足し合わせて スクリーンの1pixelを計算 23
レンダリングしてみては答え合わせを繰り返す dataset 0. データセットを用意 • 実際の物体の2D写真 • カメラの視点&撮影角度 1. カメラ位置と角度から、 スクリーンの全pixelの色を計算 cam info. cam info. cam info. cam info. cam info. (𝑐$ , 𝜎$ ) (𝑥$ , 𝑦$ , 𝑧$ , 𝜃$ , 𝜙$ ) & 𝜎 & 𝑇$ 1 − exp −𝜎$ 𝛿$ 𝑐$ $"# 2. 実際の2D画像のpixelとの2乗誤差をも とに、逆伝播でNNだけパラメタ更新 𝜎 𝑖 𝑖 誤差計算 & feed back real image 24
計算量削減のための⼯夫︓ 階層型 volume sampling 25
NeRFの計算量が⼤き過ぎる 1pixelの計算に、NNの推論が何度も必要 • sampling数/カメラray 回 Øsampling数を少しでも節約したい 💡 最初ざっくりsamplingして、重要そうなとこは細分化しよう 視線上の点1つ ごとにNNで推論 (𝑥! , 𝑦! , 𝑧! , 𝜃! , 𝜙! ) カメラ視線上の点をsampling 点の座標 & カメラの方角 (𝑐! , 𝜎! ) 点の色 & 不透明度 26
階層型 volume sampling(概要) 同一構造のNNを2つ用意 広く浅く担当NN NN①:広く浅く担当 • 空間全体の輝度場を大雑把に把握 細かいとこは自信ないけど、 大体こんな感じだと思う NN②:狭く深く担当 • 𝜎が高い(物体がある)箇所だけは詳細に把握 狭く深く担当NN ??? ??? ①と②を階層的に使ってsampling数を削減 物体無いとこは自信ないけど、 有るとこは間違いなくこう!! 27
階層型 volume sampling(詳細) 1. rayを粗く分割, 各節から1点ずつ抽出 広く浅く担当NN① 2. NN①で各点の𝑐と𝜎を計算 3. 各点->カメラに到達する光強度𝑤' (𝜎)を計算 • 𝑤! = 𝑇! 1 − exp −𝜎! 𝛿! . (p12の式と同じ) 4. 𝑤' が大きい節から更に点を抽出 𝑤! (𝜎) 狭く深く担当NN② 5. NN②で各点の𝑐と𝜎を計算 6. volume renderingへ 28
まとめ NeRFとは、 ✏ 空間上の全ての点が、“どの方向に、どんな色を発しているか”(輝度場) を知っているNNを用いて、 ✏ カメラ視線上にある点の色と不透明度をいい感じに足し合わせることで、 ✏ 任意の視点からの写真を合成できる手法 (𝑐$ , 𝜎$ ) (𝑥$ , 𝑦$ , 𝑧$ , 𝜃$ , 𝜙$ ) & 𝜎 & 𝑇$ 1 − exp −𝜎$ 𝛿$ 𝑐$ $"# 𝜎 𝑖 𝑖 29
読了感謝︕ twitter垢: https://twitter.com/ROCmannn ↑少しでもわかりやすいと思ってくれたらフォローお願いします 30