Transformer解説 ~Chat-GPTのオリジンを理解する~
79.1K Views
March 23, 23
スライド概要
Chat-GPTをはじめ、昨今の大規模言語モデル(LLM)の礎となった機械翻訳モデルTransformerの解説資料です。GPTもBERTも、基本構造はTransformerとほぼ変わりません。近年のLLMの理解には不可欠なTransformerの構造をできるだけ詳細に書き下してみました
ニューラルネットをGPU向けに最適化するお仕事をしています
関連スライド




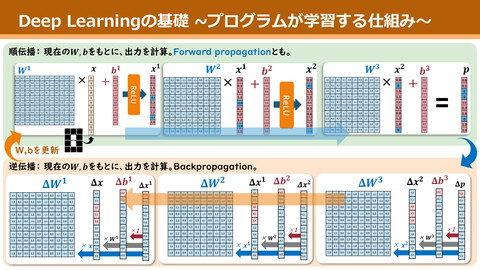

各ページのテキスト
Transformer 図だくさん解説 ~Chat-GPTの源流~ 1
⾃⼰紹介 ROCMan • 来年春から新卒GPUエンジニアの修士2年生 • 深層学習とGPUプログラミングがちょっとわかる • たまに深層学習系の論文読んでスライドにまとめてます twitter垢: https://twitter.com/ROCmannn ↑少しでもわかりやすいと思ってくれたらフォローお願いします 2
Chat-GPTを理解したい Chat-GPTすごい APIが公開され、活用アプリ&怪しい 記事が爆増 CSer, ISerとして、 根底から理解しよう 3
あくまで私は計算機屋さん 細かい理論についてはわからん ü大規模言語モデルのお気持ちには触れつつ、 あくまで、その計算フローに焦点を当てる ü本資料では学習方法は深く取り扱わない 4
⽬次 • ざっくり深層学習 • 自然言語処理モデル • RNN • Transformer 5
深層学習が何をやってるか 深層学習 …複雑な関数を、単純な線形変換()を大量に重ねて近似すること function(DNN) Rabbit Kawauso Cat 6
単純な線形変換() 𝑦 = 𝐴𝑐𝑡𝑖𝑣𝑎𝑡𝑒(𝑥𝑊 + 𝑏) (以降こいつをLinearって呼びます) Øこいつの重ね方に工夫が生まれる Ø𝑊, 𝑏の値をよしなに調整するのが学習 Activate Func 𝑥 * 𝑏 𝑊 𝑦 非線形性を生み、 表現力が向上 etc. 7
⾃然⾔語処理 人間の言語の解釈を要するタスクを機械に解かせたい Ø曖昧性の高さから、深層学習によるアプローチが主流 • 文章要約 •Q&A • 翻訳 8
Chat-GPTへの道のり GPT GPT-2 GPT-3 Chat-GPT Transformer BERT 全てはTransformerから始まった Øまずはコイツから始めましょう! 9
ざっくりTransformer “Attention Is All You Need” (Ashish Vaswani @Google Brain et al. ) 機械翻訳用の自然言語モデル 従来のRNNベースの手法から大幅に性能改善 Ø自然言語処理のbreak throughを作った革命的なモデル 10
翻訳の主流︓Encoder-Decoderモデル Encoder Decoder I am a man . 私は人だ。 単語ベクトル群 単語ベクトル群 DNN DNN 文の意味っぽいベクトル 文の意味っぽいベクトル 11
機械翻訳の祖︓RNN Recurrent Neural Network … 入力長分、共通の線形変換()を繰り返し適用するモデル 可変長の入力に対応可能、系列データ全般に強い y0 y1 s0 y2 s1 y3 s2 y4 s3 s4 Linear Linear Linear Linear Linear x0 x1 x2 x3 x4 12
RNNで機械翻訳 - Encoder部分 Encoder s0 s1 s2 s3 Linear Linear Linear Linear Linear x0 x1 x2 x3 x4 文 全 体 の 意 味 Word Embedding(実はこいつもDNN) I have a pen . 13
RNNで機械翻訳 - Decoder部分 Decoder 文 全 体 の 意 味 t0 t1 t2 t3 Linear Linear Linear Linear Linear y0 y1 y2 y3 y4 Word Embedding(実はこいつもDNN) 私は ペンを 持って いる 。 14
RNNの問題点 • 計算フローのクリティカルパスが文の長さに比例 ØGPU等の並列計算で高速化できない Encoder Decoder s0 s1 s2 s3 Linear Linear Linear Linear Linear x0 x1 x2 x3 x4 文 全 体 の 意 味 t0 have a pen t2 t3 Linear Linear Linear Linear Linear y0 y1 y2 y3 y4 Word Embedding(実はこいつもDNN) I t1 Word Embedding(実はこいつもDNN) . 15 私は ペンを 持って いる 。 15
Output Probabilities Transformer softmax Linear Layer Norm 並列性の高い計算フローを持つ Encoder-Decoder型DNN 主要なパーツ • Positional Encoding Nx • Feed-Forward Network • Layer Normalization • Multi-Head Attention + Feed Forward Layer Norm Layer Norm + + Feed Forward Multi-Head Attention Layer Norm Layer Norm + + Multi-Head Attention Masked Multi-Head Attention 〜 + 〜 xN + Input Embedding Output Embedding Inputs Outputs 16
80% 男の子 まずは超ざっくり⾒る 10% 男性 6% 4% 女の子 犬 Output Probabilities Layer Norm Decoder 1. 入力文をEncode + ⼊⼒⽂の意味 Feed Forward 2. 出力済の文と1の結果から、 Encoder 次単語の確率分布を生成 Layer Norm 3. ビームサーチで次単語確定、 出力済の文に追加 Layer Norm + Multi-Head Attention + Masked Multi-Head Attention 〜 4. 2に戻る I am a boy . 私は + 17
Output Probabilities Transformer 主要なパーツ • Positional Encoding • Feed-Forward Network • Layer Normalization Nx • Multi-Head Attention softmax Linear Layer Norm + Feed Forward Layer Norm Layer Norm + + Feed Forward Multi-Head Attention Layer Norm Layer Norm + + Multi-Head Attention Masked Multi-Head Attention 〜 + 〜 xN + Input Embedding Output Embedding Inputs Outputs 18
Positional Encoding 文の意味解釈で、各単語の位置情報は重要 LLinear層は単語の順序を考慮しない Ø入力時点で、単語自体に位置情報を明示的に埋め込む必要性 𝑑 pos 単 語 ベ ク ト ル i 𝑃𝐸 𝑝𝑜𝑠, 2𝑖 = sin !"# !" $%%%% # 𝑃𝐸 𝑝𝑜𝑠, 2𝑖 + 1 = cos( !"# !" $%%%% # ) Word Embedding I am a boy . 19
Output Probabilities Transformer 主要なパーツ • Positional Encoding • Feed-Forward Network • Layer Normalization Nx • Multi-Head Attention softmax Linear Layer Norm + Feed Forward Layer Norm Layer Norm + + Feed Forward Multi-Head Attention Layer Norm Layer Norm + + Multi-Head Attention Masked Multi-Head Attention 〜 + 〜 xN + Input Embedding Output Embedding Inputs Outputs 20
Feed-Forward Network 𝑧 = 𝑅𝑒𝐿𝑈 𝑥𝑊! + 𝑏! 𝑦 = 𝑧𝑊" + 𝑏" ØLinear x2。それだけ 𝑊! 𝑥 𝑧 𝑊" 𝑧 𝑦 ※bは省略 21
Output Probabilities Transformer 主要なパーツ • Positional Encoding • Feed-Forward Network • Layer Normalization Nx • Multi-Head Attention softmax Linear Layer Norm + Feed Forward Layer Norm Layer Norm + + Feed Forward Multi-Head Attention Layer Norm Layer Norm + + Multi-Head Attention Masked Multi-Head Attention 〜 + 〜 xN + Input Embedding Output Embedding Inputs Outputs 22
Layer Normalization Layers… I am a boy 行単位で適用 23 … … … ただの正規化もどき Ø学習の高速化や過学習の抑制に寄与 -0.9 0 -0.51.4 … LN … LN … … 1 3 2 6 … 𝑥# − 𝜇 𝐿𝑁 𝑥# = 𝛾+𝛽 𝜎 𝜇, 𝜎: 𝑥# の平均, 標準偏差 𝛾, 𝛽: パラメタ(スカラ値)
Output Probabilities Transformer softmax Linear 主要なパーツ • Positional Encoding • Feed-Forward Network • Layer Normalization Nx • Multi-Head Attention Positional Encoding Layer Norm + Feed Forward Layer Norm Layer Norm + + Feed Forward Multi-Head Attention Layer Norm Layer Norm + + Multi-Head Attention Masked Multi-Head Attention 〜 + Positional Encoding 〜 xN + Input Embedding Output Embedding Inputs Outputs 24
Multi-Head Attention 𝑴𝒖𝒍𝒕𝒊𝑯𝒆𝒂𝒅(𝑄, 𝐾, 𝑉) = 𝒄𝒐𝒏𝒄𝒂𝒕 ℎ𝑒𝑎𝑑# 𝑊 $ % ℎ𝑒𝑎𝑑# = 𝑺𝑫𝑷𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑄𝑊# , 𝐾𝑊#& , 𝑉𝑊#' 𝑺𝑫𝑷𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑄′, 𝐾′, 𝑉′ = 𝒔𝒐𝒇𝒕𝒎𝒂𝒙 𝑄′𝐾′( 𝑑 𝑉′ お気持ち • 𝑉には、整理されていない有益情報がたくさん • 𝐾は𝑉に紐づく情報がたくさん • 𝑄に近い情報がKにあれば、対応する有益情報を𝑉から抽出 25
Scaled Dot Product Attention 𝑆𝐷𝑃𝐴𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛 𝑄, 𝐾, 𝑉 = 𝑠𝑜𝑓𝑡𝑚𝑎𝑥 𝑄𝐾 ( 𝑑 𝑉 お気持ち • 𝑘# (𝑘𝑒𝑦), 𝑣# (𝑣𝑎𝑙𝑢𝑒)という対を為すベクトルが沢山 • 各入力ベクトル𝑞) と似ているkeyを集める • keyに対応するvalueたちを混ぜて出力 𝑞! 𝑞" 𝑞# 𝑞$ 𝑘! 𝑘" 𝑘# 𝑣! 𝑣" 𝑣# 26
Scaled Dot Product Attention① 𝑆𝐷𝑃𝐴𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛 𝑄, 𝐾, 𝑉 = 𝑠𝑜𝑓𝑡𝑚𝑎𝑥 𝑄𝐾 ( 𝑑 𝑉 𝑄𝐾 ( の各要素は𝑞# と𝑘) の内積 Ø𝑞# , 𝑘) の向きが近いほど値が大きいため、類似度の指標に (内積はベクトル長に比例してしまうため、 𝑑で割る) 𝑑 𝑞! 𝑞! ∗ 𝑘! 𝑞! ∗ 𝑘" 𝑞! ∗ 𝑘# 𝑞" 𝑘! 𝑘" 𝑘# 𝑘$ 𝑘%𝑞" ∗ 𝑘!𝑞" ∗ 𝑘"𝑞" ∗ 𝑘# 𝑞# 𝑞$ * 𝑞! と各keyとの 類似度ベクトル 𝑞# ∗ 𝑘!𝑞# ∗ 𝑘"𝑞# ∗ 𝑘# 𝑞$ ∗ 𝑘!𝑞$ ∗ 𝑘"𝑞$ ∗ 𝑘# 27
Scaled Dot Product Attention② 𝑆𝐷𝑃𝐴𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛 𝑄, 𝐾, 𝑉 = 𝑠𝑜𝑓𝑡𝑚𝑎𝑥 • 𝒔𝒐𝒇𝒕𝒎𝒂𝒙 𝒙 = [ 𝒆𝒙𝟏 ∑ 𝒆𝒙𝒊 , 𝒆𝒙𝟐 𝒆𝒙𝟑 , ∑ 𝒆𝒙𝒊 ∑ 𝒆𝒙𝒊 𝑄𝐾 ( 𝑑 𝑉 , …] Øベクトルを少し過激に確率分布に変換する関数 ex.) 𝑠𝑜𝑓𝑡𝑚𝑎𝑥([2,3,5]) = [0.4, 0.11, 0.85] softmax 𝑞! ~𝑘! 𝑞! ~𝑘" 𝑞! ~𝑘# 𝑞" ∗ 𝑘!𝑞" ∗ 𝑘"𝑞" ∗ 𝑘# softmax 𝑞" ~𝑘! 𝑞" ~𝑘" 𝑞" ~𝑘# 𝑞# ∗ 𝑘!𝑞# ∗ 𝑘"𝑞# ∗ 𝑘# softmax 𝑞# ~𝑘! 𝑞# ~𝑘" 𝑞# ~𝑘# 𝑞$ ∗ 𝑘!𝑞$ ∗ 𝑘"𝑞$ ∗ 𝑘# softmax 𝑞$ ~𝑘! 𝑞$ ~𝑘" 𝑞$ ~𝑘# 𝑞! ∗ 𝑘! 𝑞! ∗ 𝑘" 𝑞! ∗ 𝑘# 𝑞! と各keyとの 類似性の確率分布 28
Scaled Dot Product Attention③ 𝑆𝐷𝑃𝐴𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛 𝑄, 𝐾, 𝑉 = 𝑠𝑜𝑓𝑡𝑚𝑎𝑥 𝑄𝐾 ( 𝑉 𝑑 前stepで求めた確率分布を重みと捉え、valuesを加重平均 𝑞! ~𝑘! 𝑞! ~𝑘" 𝑞! ~𝑘# 𝑞" ~𝑘! 𝑞" ~𝑘" 𝑞" ~𝑘# 𝑞# ~𝑘! 𝑞# ~𝑘" 𝑞# ~𝑘# * 𝑞$ ~𝑘! 𝑞$ ~𝑘" 𝑞$ ~𝑘# 𝑣! % 𝑞! ~𝑘% ∗ 𝑣% 𝑣" % 𝑞" ~𝑘% ∗ 𝑣% 𝑣# % 𝑞# ~𝑘% ∗ 𝑣% % 𝑞$ ~𝑘% ∗ 𝑣% [0.4, 0.11, 0.85] 29
Multi-Head Attention 𝑀𝑢𝑙𝑡𝑖𝐻𝑒𝑎𝑑 𝑄, 𝐾, 𝑉 = 𝑐𝑜𝑛𝑐𝑎𝑡 ℎ𝑒𝑎𝑑# 𝑊 $ % ℎ𝑒𝑎𝑑# = 𝑆𝐷𝑃𝐴𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛 𝑄𝑊# , 𝐾𝑊#& , 𝑉𝑊#' Ø𝑄, 𝐾, 𝑉に様々な変換を加え、組合わせに多様性を持たせている ' ' '𝐾 𝐾 𝐾% $ ! * #!# #𝑊 𝑊 𝑊% $ '𝑉 '𝑉!' 𝑉% $ SDP Attention ℎ𝑒𝑎𝑑! * "!" 𝑊 " 𝑊𝑊 %$ * ℎ𝑒𝑎𝑑$ 𝑉 '𝑄 '𝑄!' 𝑄% $ ℎ𝑒𝑎𝑑! ℎ𝑒𝑎𝑑$ ℎ𝑒𝑎𝑑% 𝐾 * & ℎ𝑒𝑎𝑑% 𝑄 & &𝑊 𝑊 𝑊% $ ! 𝑊& 30
Multi-Head Attentionの使われ⽅① Output Probabilities Q,K,Vが全て同じ入力(文) Ø入力(文)を様々な角度で切り出した物同士 を見比べ、注目すべき箇所を決めて出力 勝手なイメージ softmax Linear Layer Norm + the violin was too big Feed Forward SDP Attention Layer Norm Layer Norm + + Feed Forward Multi-Head Attention Layer Norm Layer Norm + + Multi-Head Attention Masked Multi-Head Attention Nx Q it was too big & 𝑊% K not because put in the bag 𝑊%" V violin bag the violin 𝑊%# I could not put the violin in the bag because it was too big. 〜 + Input Embedding Inputs 〜 + Output Embedding Outputs 31 xN
Multi-Head Attentionの使われ⽅② Output Probabilities 𝑄: 加工済み出力文 𝐾, 𝑉: encoderの出力 softmax Linear Layer Norm + Feed Forward Ø出力文から、入力文のどの意味がまだ不足 しているか等を判断している? Layer Norm Layer Norm + + Feed Forward Multi-Head Attention Layer Norm Layer Norm + + Multi-Head Attention Masked Multi-Head Attention Nx 〜 + Input Embedding Inputs 〜 + Output Embedding Outputs 32 xN
Masked Multi-Head Attention Output Probabilities 主に学習のための機構 softmax Linear Layer Norm 学習時は入力文と出力文の模範解答を流す + Feed Forward 次単語予測の正解がわからないように、 出力文を一部maskするだけ Layer Norm Layer Norm + + Feed Forward Multi-Head Attention Layer Norm Layer Norm + + Multi-Head Attention Masked Multi-Head Attention Nx 〜 + Input Embedding Inputs 〜 + Output Embedding Outputs 33 xN
パーツ理解完了 最後に流れを再確認して 締めましょう 34
Output Probabilities Transformer softmax Linear Layer Norm + Feed Forward Nx Positional Encoding Layer Norm Layer Norm + + Feed Forward Multi-Head Attention Layer Norm Layer Norm + + Multi-Head Attention Masked Multi-Head Attention 〜 + Positional Encoding 〜 xN + Input Embedding Output Embedding Inputs Outputs 35
Output Probabilities 次回予告 softmax Linear Layer Norm transformerは本来翻訳家 + Feed Forward だが、意味解釈能力が超凄い これ、何にでも応用できる? N x ØGPTs, BERT Layer Norm Layer Norm + + Feed Forward Multi-Head Attention Layer Norm Layer Norm + + Multi-Head Attention Masked Multi-Head Attention 〜 + 〜 xN + Input Embedding Output Embedding Inputs Outputs 36
読了感謝︕ twitter垢: https://twitter.com/ROCmannn ↑少しでもわかりやすいと思ってくれたらフォローお願いします! 37