イラストで学ぶ音声認識 13章
>100 Views
August 26, 23
スライド概要
機械学習や音声認識に関する書籍を執筆しています。
関連スライド



各ページのテキスト
13. 音声対話システムの実現に向けて 13.1 音声対話システムの開発方法論 13.2 規則による対話管理 13.3 対話管理への統計的アプローチ ニューラルネットワークによる対話管理 • 荒木雅弘 :『イラストで学ぶ音声認識』 (講談社, 2015年) • サポートページ
13.1 音声対話システムの開発方法論
13.1 音声対話システムの開発方法論 • 発話理解 • ユーザの発話音声を入力し、音声認識後、発話理解結果(発話タイプ +「スロット名=値」の系列)をn-bestで出力 • 対話管理 • 発話理解結果を入力とし、システムの意図を生成 • 応答生成 • システムの意図を発話に変換
13.2 規則による対話管理 • 対話管理オートマトンの定義 • 状態:対話の進展状況を表し、各状態でシステム応答を定義 • 入力:ユーザ発話またはアプリケーション実行結果
13.3 対話管理への統計的アプローチ • 統計的アプローチのモチベーション • 音声の誤認識に基づく不確実性の扱い • 人手による状態遷移記述の難しさへの対処 • 信念ネットワークによる対話モデル [Meng+, 2003] • 入力の不確実性への対処として、タスク中のスロット値の確からしさ を確率変数として捉える • 確率変数の集合から、システムの行為へのマッピングをコーパスから 学習
13.3 対話管理への統計的アプローチ • MDP による対話管理 • 対話をマルコフ決定過程として定式化 • 時刻 t におけるシステムの状態: st ∈ S • 時刻 t におけるシステムの行為: at ∈ A • 報酬: rt = r(st, at) ∈ R • 状態遷移確率: p(st+1 | st, at) • 強化学習によって最適政策(期待報酬を最大とする状態から行為へ のマッピング)の学習をおこなう
13.3 対話管理への統計的アプローチ
13.3 対話管理への統計的アプローチ • POMDPによる対話管理 • 現在の状態を、取り得るすべての状態の確率分布(信念)として表現 • 信念の表現 ot : 時刻tでの観測 • 信念と行為のマッピングを強化学習 • 通常は確率分布の離散化など近似手法の導入が必要
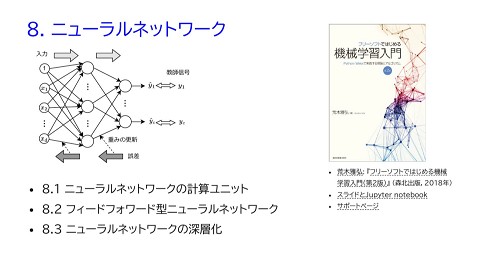
ニューラルネットワークによる対話管理 • RNNによる信念の推定 • 対話の開始時点から時刻 t までの観測に基づいた信念の表現 • リカレントネットワーク (RNN) で表現可能 入力:ベクトル表現 されたユーザ発話 出力:信念
ニューラルネットワークによる対話管理 • RNNベース言語モデルからの応答生成 [Wen+ 2015] 入力:inform(name=Seven_Days, food=Chinese) dialog act 1-hot 表現に変換 [0, 0, 1, 0, ...,0, 1, 0, ..., 0, 1, 0] :どの特徴値を入力とするかを選択するゲート </s> SLOT_NAME serves SLOT_FOOD . </s> Seven_Days serves Chinese food . スロット名へ変換 </s> </s>